
Avoiding game crashes related to linked lists

In this post I’m going to talk about linked lists, a seemingly trivial subject that many programmers — even good ones — seem to get terribly wrong!
Then I’m going to share techniques (with source code) to make your game engine code simpler, faster, more memory efficient and more reliable. Wow!
TL;DR: Here’s the source code which implements an intrusive doubly-linked list that’s better than std::list and boost intrusive lists (for some definition of better).
Using std::list
Here’s how a programmer declares a linked list using standard STL (cribbed from the aforementioned article):
struct person {
unsigned age;
unsigned weight;
};
std::list <person*> people;After adding a few members to the linked list, we’d get something that looks like this in memory:
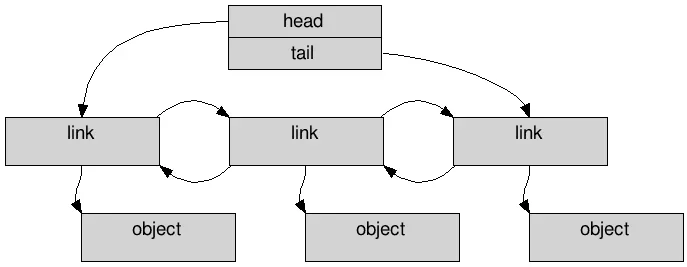
A doubly-linked list created using C++ std::list
Here is code that safely removes a person record from the linked list:
// NOTE: O(N) algorithm
// -- requires list scanning
// -- requires memory deallocation
void erase_person (person *ptr) {
std::list <person*>::iterator it;
for (it = people.begin(); it != people.end(); ++it) {
if (*it != ptr)
continue;
people.erase(it);
break; // assume person is only linked once
}
}The unlinking code is awful: for a list with N entries, on average it is necessary to scan N/2 entries to find the element we’re interested in removing, which is why a linked list is a bad choice for storing records that need to be accessed in random order.
More importantly, it’s necessary to write list-removal functions like the code above, which takes programmer dev-time, slows compilation, and can have bugs. With a better linked-list library, this code is entirely unnecessary.
Using intrusive lists
Let’s talk about an alternative to std::list using intrusive lists.
Intrusive lists are ones that require the “link” fields to be embedded directly into the structure being linked. Unlike externally linked lists, where a separate object is used to hold a pointer to the object and previous/next links, the intrusive list makes its presence known in the structure being linked.
Here’s code that re-implements the example above so that it use intrusive links:
struct person {
TLink link; // The "intrusive" link field
unsigned age;
unsigned weight;
};
TListDeclare<person, offsetof(person, link)> people;I use a #define macro to avoid code-duplication and typo-errors, so my list definition would actually look like this:
LIST_DECLARE(person, link) people;In comparison to std::list, when viewing the memory layout you can see that there are fewer objects allocated in memory:
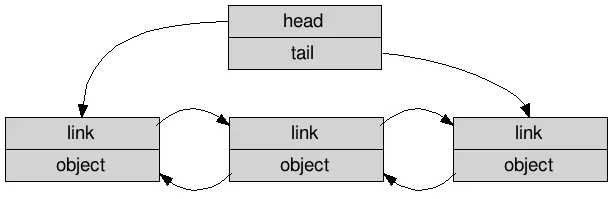
A doubly-linked intrusive list
The code to remove an element from the list is simpler and faster, and does not require memory deallocation:
// NOTE: O(1) algorithm
// -- no list traversal
// -- no memory deallocation
void erase_person (person *ptr) {
ptr->link.Unlink();
}And even better, if you delete a record that’s part of an intrusive list, it automatically unlinks itself from the list:
void delete_person (person *ptr) {
// automagically unlinks person record no matter
// which linked list it is contained within
delete ptr;
}Why intrusive lists are better
If you’ve made it this far, you probably have an inkling about why intrusive lists are better than externally-linked lists in many cases; here are the ones I’ve come up with:
- Because the link fields which are used to include an object within a linked-list are embedded within the object itself it is no longer necessary to allocate memory to link an item onto a list, nor deallocate memory when unlinking.
ApplicationSpeed++.MemoryUtilization–. - When traversing objects stored on an intrusive linked list, it only takes one pointer indirection to get to the object, compared to two pointer indirections for std::list. This causes less memory-cache thrashing so your program runs faster — particularly on modern processors which have huge delays for memory stalls.
ApplicationSpeed++.CacheThrashing–. - We reduce code failure paths because it is no longer necessary to handle out-of-memory exceptions when linking items.
CodeObjectSize--.CodeComplexity–. - Most importantly, objects are automatically removed from the lists they’re linked into, eliminating many common types of bugs. `ApplicationReliability++.
How do I link an object to multiple lists?
One of the great benefits of intrusive lists is that they just work. Let’s see how:
struct employee {
TLink<employee> employeeLink;
TLink<employee> managerLink;
unsigned salary;
};
struct manager : employee {
LIST_DECLARE(employee, managerLink) staff;
};
LIST_DECLARE(employee, employeeLink) employees;
void friday () {
// Hire Joe, a cashier
employee * joe = new employee;
joe->salary = 50 * 1000;
employees.LinkTail(joe);
// Hire Sally, a shift manager
manager * sally = new manager;
sally->salary = 80 * 1000;
employees.LinkTail(sally);
sally->staff.LinkTail(joe);
// Oops, Joe got caught with his hand in the till
delete joe;
// Now that Joe is gone, Sally has no reports
ASSERT(sally->staff.Empty());
// And she is now the only employee
ASSERT(employees.Head() == sally);
ASSERT(employees.Tail() == sally);
}Pretty nifty, huh? You can see how a lot of common errors can be avoided when cleanup is automatic.
There’s a fly in my soup
Some folks might be concerned that their objects now contain those intrusive link fields which are unrelated to the data the object is supposed to contain. The person record is now “polluted” with external “stuff”.
This does make it harder to do leet-programmer stuff like directly writing the record to disk (can’t safely write pointers), using memcmp to compare objects (those pesky pointers again) and similarly hackish stuff. But you shouldn’t be doing that anyway. Reliability is more important than speed, and if you’re reduced to using those hacks for speed-gains your program needs help.
Where is my object linked?
When using intrusive lists your program must declare which lists a record will be embedded within when declaring those structures. In most cases this is trivial, but some cases require finesse:
// Some3rdPartyHeaderYouCannotChange.h
struct Some3rdPartyStruct {
// lots of data
};
// MyProgram.cpp
struct MyStruct : Some3rdPartyStruct {
TLink<MyStruct> link;
}
LIST_DECLARE(MyStruct, link) mylist;Of course if you don’t control the structure definition nor the code where it is allocated, which might be true when working with third-party libraries you can fall back to using std::list.
Cautions for threaded code
When writing multi-threaded code it is important to remember that a delete operation will call the destructors for each intrusive link field to remove that element from the list.
If the object being deleted has already been unlinked from all lists, then no problem. But if the object is still linked to a list it will be necessary to use locks to protect against race conditions. Here are some solutions from worst to best:
// Wrap destructor with a lock to avoid race condition
// Downsides:
// lock held while calling destructor
// lock held during memory free
void threadsafe_delete_person (person *ptr) {
s_personlock.EnterWrite();
{
delete ptr;
}
s_personlock.LeaveWrite();
}
-- or --
// Wrap unlink with lock to avoid race condition.
// Avoids downsides of the solution above, but
// Unlink() will be called again safely but
// unnecessarily in the TLink destructor.
void threadsafe_delete_person (person *ptr) {
s_personlock.EnterWrite();
{
ptr->link.Unlink();
}
s_personlock.LeaveWrite();
delete ptr;
}
-- or --
// Same as above, but less fragile; since the
// unlinking is done in the destructor it is
// impossible to forget to unlink when calling
// delete
person::~person () {
s_personlock.EnterWrite();
{
link.Unlink();
}
s_personlock.LeaveWrite();
}
-- or --
// Same as above but reduces contention on lock
person::~person () {
if (link.IsLinked()) {
s_personlock.EnterWrite();
{
link.Unlink();
}
s_personlock.LeaveWrite();
}
}You can probably tell I’ve done this a lot, huh?
Assignment and copy-construction for links and lists
It’s not possible to copy-construct or assign objects linked into intrusive lists, nor to do the same for the lists themselves. In practice this is not a limitation that you’ll run into. For the special case where it is necessary to move items from one list to another, it’s possible to write a function to splice elements from one list onto another.
Why not use boost intrusive lists?
Boost intrusive list.hpp implements a similar intrusive list, designed to solve every linked list problem you’ve ever had, and consequently it’s daunting to use. Boy howdy did they make it complicated — unnecessarily so, I think.
If you read the source code, I hope you’ll find it straightforward. For a start, the entire intrusive linked-list, including the comments and MIT license, clocks in at under 500 lines.
Compare this with boost intrusive list.hpp — which admittedly does have more functionality — at 1500 lines not including the eleven (!!) subsidiary headers filled with unreadable modern C++ templately stuff.
Example use-case where std::list would break down
Here’s an example of some code I implemented in ArenaSrv, the server framework used for all Guild Wars services (both GW1 and GW2), rewritten for clarity and brevity.
The code is designed to prevent a particular type of attack against a network service called Slowloris. What Slowloris does is to gradually connect lots of sockets to a single network service until it has eventually saturated the server with connections, at which point the server generally stops behaving properly. Apache web servers are particularly vulnerable to Slowloris, though many other network services have similar issues.
//*********** SLOWLORIS PREVENTION FUNCTIONS ***********
// Mark connection so it will be closed "soon" unless
// a complete message is received in the near future
void Slowloris_Add (Connection * c) {
s_pendingCritsect.Enter();
{
// List is kept in sorted order; newest at the tail
s_pendingList.LinkTail(c);
c->disconnectTime = GetTime() + DEFEAT_SLOWLORIS_TIME;
}
s_pendingCritsect.Leave();
}
// Remove connection from "close-me-soon" list
void Slowloris_Remove (Connection * c) {
s_pendingCritsect.Enter();
{
s_pendingList.Unlink(c);
}
s_pendingCritsect.Leave();
}
// Periodically check "close-me-soon" list
void Slowloris_CheckAll () {
s_pendingCritsect.Enter();
while (Connection * c = s_pendingList.Head()) {
// Since the list is sorted we can stop any
// time we find an entry that has not expired
if (!TimeExpired(GetTime(), c->disconnectTime))
break;
s_pendingList.Unlink(c);
c->DisconnectSocket();
}
s_pendingCritsect.Leave();
}
//*********** SOCKET FUNCTIONS ***********
void OnSocketConnect (Connection * c) {
Slowloris_Add(c);
}
void OnSocketDisconnect (Connection * c) {
Slowloris_Remove(c);
delete c;
}
void OnSocketReadData (Connection * c, Data * data) {
bool msgComplete = AddData(&c->msg, c->data);
if (msgComplete) {
Slowloris_Add(c);
ProcessMessageAndResetBuffer(&c->msg);
}
}You wouldn’t want to use std::list for this type of problem because, each time it became necessary to remove a connection from the “close-me-soon” list it would be necessary to traverse 50% of the list (on average). Since some Guild Wars 1 services hosted as many as 20K connections in a single process, this would entail scanning 10000 items on average — not a good idea!
Credit where credit is due
I didn’t invent this linked-list technique. The first time I encountered it was in Mike O’Brien’s code for Diablo, included in Storm.dll. When Mike and I started ArenaNet, the first code that Mike wrote was a better version of that linked-list code.
Upon leaving ArenaNet, I discovered that after ten years of coding with intrusive lists — and the attendant lack of worry about silly linked-list bugs — I needed to re-implement the code again because no better alternatives existed (boost notwithstanding). Some trial and error ensued!
In order to avoid this constant rewriting, I have open-sourced the code using the MIT license, which means you get to use it with no commercial limitations.
Conclusions
Well there you go: an explanation of the uses of intrusive lists. They’re awesome for writing more reliable code because they cleanup after themselves (caveat: multithreaded code).
The programming team that implemented Guild Wars included more than ten coders who were recent college graduates. Had we turned them loose on a game engine to write code using std::list the bug count would have been much higher — meaning no offense to those programmers at all; they’re great folks. By giving them access to tools like these we were able to write 6.5 million lines of code — a huge scope for a game — with exceptional stability and reliability.
A key goal of good programming is to increase reliability. By creating collection classes that “just work” we can go a great distance towards that end.